

今回は機械学習で使える無料のデータセット8選をそれぞれ用途別にご紹介します。
本記事のデータを活用すれば機械学習の基礎であるScikit Learnを用いた分類モデル、回帰モデル等の練習に役立つこと間違いなし!
実際のデータ読み込み用のコードも記載していますので、ご自身でのデータセットを使用したいときの参考にしてください。

いろいろ学んだことを試してみたいけどちょうどいいデータがない。。
どの程度のデータがあれば機械学習モデルを構築できるのか知りたい!

本記事ではそんな疑問にお答えします。
こんな方におすすめの記事
- 機械学習における分類モデル、回帰モデルの練習をしたい
- 機械学習用のデータがどの程度のものか知りたい
- 実際のデータ分析コンペで使われているデータを見てみたい
ボストン市の住宅価格データ(Boston house prices dataset)

機械学習を学んだことがある方なら一度は聞いたことのあるボストン市の住宅価格データです。
このデータセットには住宅周辺の犯罪率や、住宅の部屋数、広さなどの情報が説明変数として用意されています。
アメリカならではの指標となっているため、同じような説明変数で日本の住居、マンション等の価格予測に転用は難しいかもしれませんが、回帰予測の方策を練る練習にはもってこいかと思います。
広さごとの価格分布などの可視化練習にもおすすめです!
データ詳細
- データ数 : 506
- カラム数 : 14 ( 住宅価格の中央値が通常目的変数として使われる)
- データ用途 : 回帰予測
データの読み込み
それでは実際にデータを読み込んでみましょう!
#Scikit Learn ->http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_boston.html#sklearn.datasets.load_boston
# ボストン市の住宅価格データ(Boston house prices dataset)
import pandas as pd
from sklearn.datasets import load_boston
# データフレームのセット
dataset = load_boston()
X = pd.DataFrame(dataset.data, columns=dataset.feature_names)
y = pd.Series(dataset.target, name='MEDV')
# データ形状の確認
print('----------------------------------------')
print('df_boston shape: (%i,%i)' %X.join(y).shape)
print('-----------------------------------------')
display(X.join(y).head(5))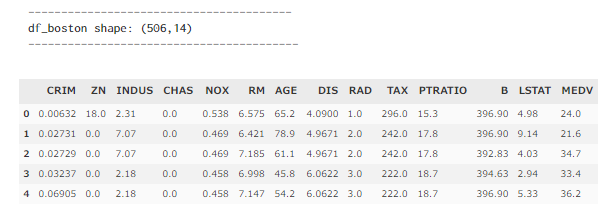
回帰予測では教科書でもよく使われるデータセットだね!
アヤメの品種データ(Iris plants dataset)

次は機械学習を学んだことがある方なら一度は聞いたことのあるアヤメの品種データです。
アヤメの品種の「Setosa」 「Versicolor」「 Virginica」の3品種をそれぞれのがく片の大きさ、花びらの特徴などから分類するタスクの練習に広く用いられています。
データ量も少なく、可視化してもきれいにクラスター分布が見えるので初心者にはもってこいのデータセットかと思います。
データ詳細
- データ数 : 150
- カラム数 : 5 (アヤメの品種クラス [ 0,1,2] が目的変数として使われる)
- データ用途 : 3クラス分類
データの読み込み
それでは実際にデータを読み込んでみましょう!
#Scikit Learn -> http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html#sklearn.datasets.load_iris
# アヤメの品種データ(Iris plants dataset)
import pandas as pd
from sklearn.datasets import load_iris
# データフレームのセット
dataset = load_iris()
X = pd.DataFrame(dataset.data,columns=dataset.feature_names)
y = pd.Series(dataset.target, name='Variety')
# データ形状の確認
print('----------------------------------------')
print('df_iris shape: (%i,%i)' %X.join(y).shape)
print('-----------------------------------------')
display(X.join(y).head(5))()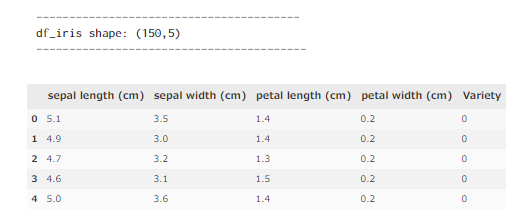
データ量も少ないからお試しにはちょうどいいね!
乳がんデータ(Breast cancer wisconsin dataset)

次は乳がんの診断データセットです。
乳がん腫瘍の見た目などの各種特徴が説明変数として与えられており、目的変数として悪性/良性の腫瘍どちらなのかデータが記載されています。
比較的に説明変数も多く、データ数もあるので次元削減などの練習にはもってこいのデータセットかと思います。
こちらのデータを使用して決定木モデルでの重要説明変数の可視化を以下の記事で行っていますので是非参考にしてください。
データ詳細
- データ数 : 569
- カラム数 : 31 (乳がんの良性/悪性腫瘍の診断結果 [ 0,1] が目的変数として使われる)
- データ用途 : 2クラス分類
データの読み込み
それでは実際にデータを読み込んでみましょう!
#Scikit Learn ->http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_breast_cancer.html#sklearn.datasets.load_breast_cancer
#乳がんデータ(Breast cancer wisconsin dataset)
import pandas as pd
from sklearn.datasets import load_breast_cancer
# データフレームのセット
dataset = load_breast_cancer()
X = pd.DataFrame(dataset.data,columns=dataset.feature_names)
y = pd.Series(dataset.target, name='Target')
# データ形状の確認
print('----------------------------------------')
print('df_cancer shape: (%i,%i)' %X.join(y).shape)
print('-----------------------------------------')
display(X.join(y).head(5))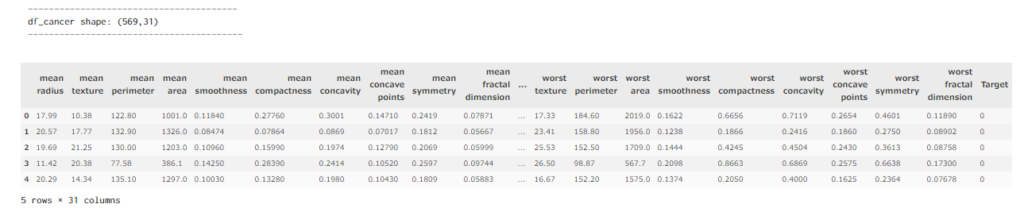
説明変数が多いから、どれが重要な指標なのか絞り込む練習に使おう!
数字の手書き文字データ (Optical recognition of handwritten digits dataset)
次は手書き数字のデータセットです。
8 x 8の分解能で表示される0-9の10種類の手書き文字データになります。説明変数カラムは計64(8 x 8)あり、それぞれ色の濃淡の度合いの情報が記載されています。
9つの数字が目的変数として用意されているので、多クラス分類の練習におススメです。
データ詳細
- データ数 : 1797
- カラム数 : 65 (0-9の数字指標 が目的変数として使われる)
- データ用途 :多クラス分類
データの読み込み
それでは実際にデータを読み込んでみましょう!
#Scikit Learn -> http://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_digits.html#sklearn.datasets.load_digits
# 数字の手書き文字データ (Optical recognition of handwritten digits dataset)
import pandas as pd
from sklearn.datasets import load_digits
# データフレームのセット
dataset = load_digits(n_class=10)
X = pd.DataFrame(dataset.data,columns=dataset.feature_names)
y = pd.Series(dataset.target, name='Target')
# データ形状の確認
print('----------------------------------------')
print('df_digit shape: (%i,%i)' %X.join(y).shape)
print('-----------------------------------------')
display(X.join(y).head(5))
手書き数字のデータセットもいろんな本にでてくるよね!
国連提供 温室効果ガスデータセット 1990-2017 (International Greenhouse Gas Emissions)

以降はKaggleからのデータセットになります。
ご自身の環境下でデータを用いる場合、Kaggleアカウントを作成、各コンペサイトからcsvデータをダウンロードする形でデータを取得してください。
まずは国連の提供する温室効果ガスのデータセットです。
1990-2017年にかけての国別温室効果ガスの排出量が記録されています。温室効果ガスの種類別(CO2、CH4など)にカテゴリーも分けられているので、自分が見たい指標だけに絞ることも可能です。
カテゴリー別の指標の差を可視化したり、時系列データを扱いたいときにおススメです。
データ詳細
- データ数 : 8406
- カラム数 : 4 (国、年、排出量、排出温室効果ガス)
- データ用途 :時系列予測、カテゴリー別可視化
以下の記事でこちらのデータを使った可視化を試しています。↓

データの読み込み
それでは実際にデータを読み込んでみましょう!
#Kaggle-> https://www.kaggle.com/unitednations/international-greenhouse-gas-emissions
#国連提供 温室効果ガスデータセット 1990-2017
import pandas as pd
from sklearn.datasets import load_breast_cancer
#データの読み込み データの保存先は要変更
directory = ["../Data"]
file = ["greenhouse_gas_inventory_data.csv"]
# データフレームのセット
df_emission = pd.read_csv(os.path.join(directory[0], file[0]))
Column_List = df_emission.columns
# データ形状の確認
print('--------------------------------------------------')
print('df_emission_shape: (%i,%i)' % df_emission.shape)
print('--------------------------------------------------')
df_emission.head()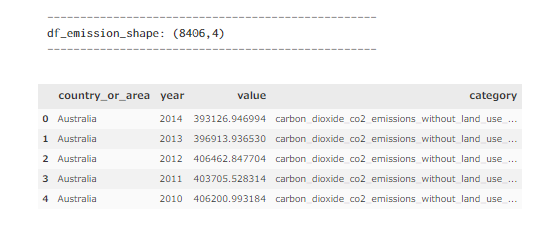
日本の排出量は世界に比べてどのくらいなんだろう?
タイタニックデータセット (Titanic - Machine Learning from Disaster)

次はとても有名なタイタニック号の生存者データセットです。
Kaggleに登録したらまずはこのコンペで練習をするのが通例のような感じになっています!
乗客の説明変数として年齢や部屋の等級などが記載されており、その情報から乗客が生存したか亡くなってしまったかを予測します。
機械学習の初心者が分類タスクを扱うにはもってこいのデータです!
データ詳細
- データ数 : 891
- カラム数 : 12 (Survivedのカラム[0,1]が目的変数として使われる)
- データ用途 :2クラス分類
データの読み込み
それでは実際にデータを読み込んでみましょう!
#Kaggle-> https://www.kaggle.com/c/titanic
#タイタニックデータセット (Titanic - Machine Learning from Disaster)
import pandas as pd
from sklearn.datasets import load_breast_cancer
#データの読み込み データの保存先は要変更
directory = ["../Data"]
file = ["taitanic.csv"]
# データフレームのセット
df_taitanic = pd.read_csv(os.path.join(directory[0], file[0]))
Column_List = df_taitanic.columns
# データ形状の確認
print('--------------------------------------------------')
print('df_taitanic_shape: (%i,%i)' % df_taitanic.shape)
print('--------------------------------------------------')
df_taitanic.head()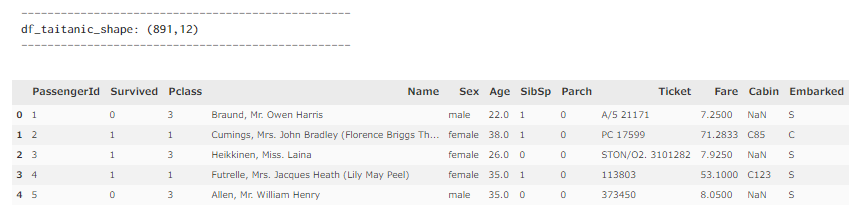
公開されているKagglerたちのノートを参照するとすごく勉強になるよ!
Bitcoin価格予測用データ (Bitcoin Price Prediction )

次はBitcoinの価格予測用データセットです。
機械学習を使ってBitcoinの価格予測でまる儲け!皆さん考えますよね(笑)
過去のデータ指標を使って自分の予測モデルを構築する練習に使用してみてはいかがでしょうか?本データセットには一日ごとのロウソクチャートの情報が含まれています。
過去のデータを考慮した予測モデルを構築する必要があるので、RNNなどの練習にもってこいです。
RNNとは?
Recurrent Neural Networkの略称。時系列データの予測でよく使われるディープラーニングの代表的手法です。
データ詳細
- データ数 : 1556
- カラム数 : 7 (Market CapカラムがBitcoinの価格)
- データ用途 :時系列予測
データの読み込み
それでは実際にデータを読み込んでみましょう!
#Kaggle-> https://www.kaggle.com/team-ai/bitcoin-price-prediction?select=bitcoin_price_Training+-+Training.csv
#Bitcoin価格予測用データ (Bitcoin Price Prediction (LightWeight CSV))
import pandas as pd
from sklearn.datasets import load_breast_cancer
#データの読み込み データの保存先は要変更
directory = ["../Data"]
file = ["bitcoin_price_Training - Training.csv"]
# データフレームのセット
df_fintech = pd.read_csv(os.path.join(directory[0], file[0]))
Column_List = df_fintech.columns
# データ形状の確認
print('--------------------------------------------------')
print('df_fintech_shape: (%i,%i)' % df_fintech.shape)
print('--------------------------------------------------')
df_fintech.head()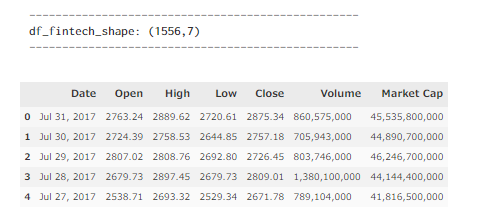
もっと時間の分解の高いデータが欲しければ、いろんなところで提供されているので探してみよう!
UFO目撃データ (UFO Sightings)

次は斜め上からUFOの目撃データセットです。
過去100年間のUFO目撃事例が場所、出現時間、詳細情報とともに約8万件登録されています。
このデータをもとにどこにUFOが現れるのか予測モデルを構築できるかも、、!?
データ詳細
- データ数 : 80332
- カラム数 : 11
- データ用途 :???
データの読み込み
それでは実際にデータを読み込んでみましょう!
#Kaggle-> https://www.kaggle.com/NUFORC/ufo-sightings
#UFO目撃データ (UFO Sightings)
import pandas as pd
from sklearn.datasets import load_breast_cancer
#データの読み込み データの保存先は要変更
directory = ["../Data"]
file = ["ufo_sightings.csv"]
# データフレームのセット
df_ufo = pd.read_csv(os.path.join(directory[0], file[0]))
Column_List = df_ufo.columns
# データ形状の確認
print('--------------------------------------------------')
print('df_ufo_shape: (%i,%i)' % df_ufo.shape)
print('--------------------------------------------------')
df_ufo.head()
データを眺めるだけでもおもしろいね!
まとめ
以上、機械学習に使える無料のデータセットを紹介しました。
意外といろいろ試してみたくても都合のいいデータがないことがありますよね、今回ご紹介した例を含め、分析の目的別に使いまわせるデータを持っておくと何かと便利かと思います。
本記事が皆さんの参考になれば幸いです。
最後に紹介です!
もっと詳しくPythonの使い方を勉強したいと思ったそこのアナタ!pythonを用いたコーディング学習にはData Campがおススメです!
詳細に関してはこちらで紹介しています。↓
こちらもぜひ参考にしてください。

それでは本日は以上でした!