

本日はPandasでのgroupby/pivot_tableでのカテゴリー別データの集計方法に関して解説します。
大量のデータを扱いだすとカテゴリーごとに傾向を見たり、集計した統計量を確認したいときがありますよね。
今回はKaggleにて提供されているTaitanic号のデータを用いてカテゴリーごとのデータ集計方法を解説していきます。
最後まで読めばデータ集計の基本はできるようになるかと思いますので、ぜひ参考にしていってください。

Excelでピボットテーブルは作ったことあるけどPythonではどうやってやるの?
Pandasでのデータ集計方法の基礎を知りたい!

こんな方におすすめの記事
- Pandasにおけるgroupby/ pivot_tableメソッドの使い方を知りたい
- PythonにおけるPandasを使ったデータ集計の方法を知りたい
- ExcelだとPivot Tableを扱うにはデータが多すぎるので、Pythonでの集計方法を知りたい
本記事ではそんな疑問にお答えします。
groupby/pivot_tableでのカテゴリー集計方法
PythonにおけるPandasモジュールではgroupby、pivot_tableというメソッドが用意されています。
本メソッドを用いることで以下ができるようになります。
groupby/pivot_table できること
- カテゴリー情報別にそのほかの数値指標の統計量をまとめられる
- 統計量のまとめ方を指定できる(平均/中央値/合計 等)
- 複数カテゴリーの統計量集計も可能
文章だとわかりづらいですよね。
実際にコードを見ながら学習していきましょう!
データが多いと何を見ていいかわからなくなるけど、落ち着いて一つ一つ整理していこう!
データの読み込み
今回は以下の記事でも紹介しているKaggleのTaitanic号のデータを使いながらgroupby/pivot_tableでのデータ集計を行っていきます。

タイタニック号のデータには乗客の説明変数として性別、年齢、部屋の等級などがあり、カテゴリーデータと数値データ両方のデータが記載されています。
今回はそれらのカテゴリデータを使い、各数値データの指標の統計量を見ていきます。
それではまず以下のコードでデータを読み込んでいきましょう!
#Kaggle-> https://www.kaggle.com/c/titanic
#タイタニックデータセット (Titanic - Machine Learning from Disaster)
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
# データフレームのセット
df_taitanic = pd.read_csv("../Data/taitanic.csv")
Column_List = df_taitanic.columns
# データ形状の確認
print('--------------------------------------------------')
print('df_taitanic_shape: (%i,%i)' % df_taitanic.shape)
print('--------------------------------------------------')
df_taitanic.head()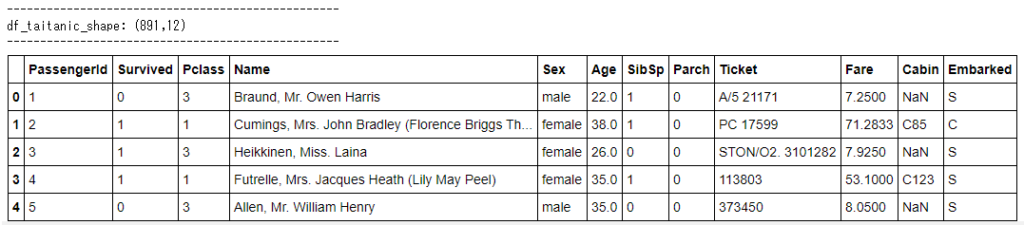
生存したか否か(Survived)は0,1のカテゴリー変数、また性別(Sex)、チケットクラス(PClass)なども同じくカテゴリーで示されているようですね!
これらのデータに対して統計量を整理していきます。
名前とかはバラバラでカテゴリー別にはできなそう。ただMr/Missなどの敬称を絞り込んだらグループ分けできるかも!
groupbyによるデータ集計
単一カテゴリの集計
それではまず上記で作成したタイタニック号データのデータフレーム(df_taitanic)に対してgroupbyによるデータ整理を行っていきます。
まず本データセットのSurvivedカラムの情報を用いて生存/亡くなった方のそれぞれの平均年齢を見てみましょう。

#生存/亡くなった方の年齢平均
print(df_taitanic.groupby(["Survived"])["Age"].mean())Survived
0 30.626179
1 28.343690
Name: Age, dtype: float64
たった一行のコードで亡くなった方、生存された方のそれぞれのグループの平均年齢を得られましたね!
年齢が少し若いほうが生存率は高かったようです。
複数カテゴリの集計
上記では1カラムのみを選択しましたが、グループ化するカラム名は複数条件の指定ができます!
次は亡くなった方、生存された方のチケットクラスごとの平均年齢を見てみましょう!
やり方は簡単!ただgroupbyの集計したいカテゴリにPclassのカラム名称を足すだけです!
#生存/亡くなった方の各Pclassごとの年齢平均
print(df_taitanic.groupby(["Survived","Pclass"])["Age"].mean())Survived Pclass
0 1 43.695312
2 33.544444
3 26.555556
1 1 35.368197
2 25.901566
3 20.646118
Name: Age, dtype: float64
Survivedのクラスの中にPclassのカテゴリーが追加されましたね!
チケットクラスは数字が小さいほど上級クラスになるので、Survivedの0、1にかかわらず年齢の高い方が多いことが分かります。
どのクラスでも若い方の方が生存確率は高かったようですね。
複数カテゴリ + 複数統計量の集計
次は複数統計量を表示する方法について解説します。
指定したカテゴリーに対して平均以外の指定した統計量も抽出することができます。
今回は最小値、最大値、平均値を抽出してみましょう!

#生存/亡くなった方の年齢のmin/max/mean
print(df_taitanic.groupby(["Survived"])["Age"].agg([min,max,np.mean]))
#生存/亡くなった方の各Pclassごとの年齢min/max/mean
print(df_taitanic.groupby(["Survived","Pclass"])["Age"].agg([min,max,np.mean]))
min max mean
Survived
0 1.00 74.0 30.626179
1 0.42 80.0 28.343690
min max mean
Survived Pclass
0 1 2.00 71.0 43.695312
2 16.00 70.0 33.544444
3 1.00 74.0 26.555556
1 1 0.92 80.0 35.368197
2 0.67 62.0 25.901566
3 0.42 63.0 20.646118
上記で集計した平均値に加えて年齢の最小値、最大値も表示されました!
年齢の最小値が1以下となっているのは乳児を意図しているのか、エラーなのか確かめる必要がありそうですね。
Excelだと結構手間がかかる処理だけどPandasだと一瞬だね!
pivot_tableによるデータ整理
次はpivot_tableによるデータ集計を行います!
pivot_tableのメソッドではより簡単にデータを集計した新たな表を作ることができます。
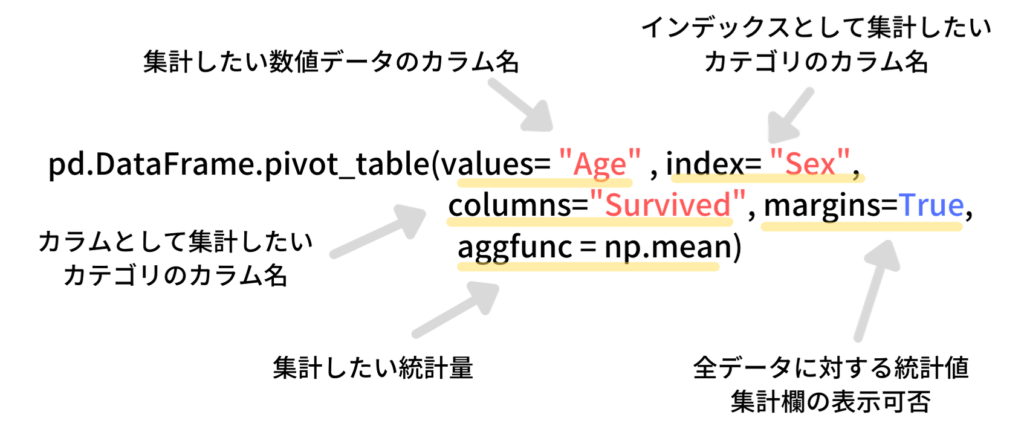
ではまず初めにpivot_tableを用いて同じようにタイタニック号のデータから性別ごとの年齢の平均および中央値を見ていきます。
#ピボットテーブルでの性別別 年齢平均値と中央値の取得
print(df_taitanic.pivot_table(values= "Age" , index= "Sex", aggfunc= [np.mean, np.median])) mean median
Age Age
Sex
female 27.915709 27.0
male 30.726645 29.0
簡単に算出できましたね!女性の方が若い方が多そうです。
pivot_tableでのその名の通り、行、列にそれぞれカテゴリーの値を追加して指定の数値データに対する新たな表を作ることができます。
上記の例では列のカテゴリーを追加していません。次の例でpivot_tableの本領を見ていきましょう。
#ピボットテーブルでの生存者/死亡者それぞれの性別別 年齢平均値の取得
print(df_taitanic.pivot_table(values= "Age" , index= "Sex", columns="Survived", margins=True, aggfunc = np.mean))
Survived 0 1 All
Sex
female 25.046875 28.847716 27.915709
male 31.618056 27.276022 30.726645
All 30.626179 28.343690 29.699118
行に性別("Sex")、列に生存したか否か("Survived")のカテゴリー数を持ち、それぞれの条件での年齢の平均値を示す表が新たに作成されました!
margins=TrueにしているためAllの項目が追加され、各指標のデータ全体に対する平均も記載されていますね。
行、列に何のカテゴリを入れるか、どんな統計量を入れるかを指定すればいいだけ!簡単だね!
まとめ
本日はgroupby、pivot_tableのメソッドによる統計量の抽出方法を紹介しました。
pandasでは大量のデータに対する様々なデータ処理が可能なので、本メソッドはそのほんの一部です。
ただデータの傾向を見るためには頻繁に使うメソッドになってくるので、覚えておいて損はないと思います。
これを機にもっと詳しくPythonの使い方を勉強したいと思ったそこのアナタ!pythonを用いたコーディング学習にはData Campがおススメです!
詳細に関してはこちらで紹介しています。↓
こちらもぜひ参考にしてください。

それでは本日は以上でした!